Audio Commons Audio Extractor
As part of the Audio Commons Ecosystem, we have been developing a number of tools for the automatic analysis of audio content (see Annotation tools in the diagram below). These tools are designed to automatically extract musical audio features such as tonal and rhythmic information, and non-musical audio features such as timbral qualities.
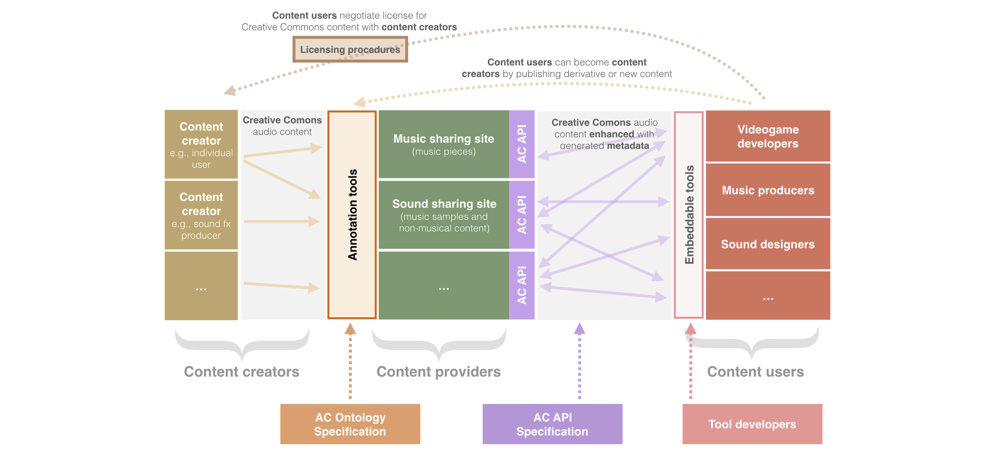
Figure 1. General diagram of the Audio Commons Ecosystem
In this blog post we give an overview of the Audio Commons Audio Extractor, an audio analysis tool which, in a single and easy to use package, includes some of the other tools developed for Audio Commons. The Audio Commons Extractor can therefore be used to automatically analyse a collection of audio files and provide metadata so that the files can be published in the Audio Commons Ecosystem.
In particular, the Audio Commons Audio Extractor incorporates the annotation tools developed for analysing music samples (see deliverable D4.2), some of the tools developed for the analysis of music pieces (see deliverable D4.3), and the timbral models developed to annotate non-musical sound properties (see deliverable D5.2). All these tools are still work in progress and might not always work as expected. Don’t hesitate to report issues and provide feedback in our code repository. Updated versions of the individual analysis tools and the Audio Commons Audio Extractor are expected to be released by the end of 2018.
Let’s see an example of the output of the Audio Commons Audio Extractor when analysing this sound from Freesound:
{
"duration": 8.0,
"lossless": 1.0,
"codec": "flac",
"bitrate": 0.0",
"samplerate": 44100.0,
"channels": 2.0,
"audio_md5": "e23cb36795e97b6fde113048b9192be7",
"loudness": -15.266595840454102,
"dynamic_range": 0.3832254409790039,
"temporal_centroid": 0.49197596311569214,
"log_attack_time": 0.302259236574173,
"filesize": 975638,
"single_event": false,
"tonality": "F major",
"tonality_confidence": 0.6949952244758606,
"loop": true,
"tempo": 120,
"tempo_confidence": 1.0,
"note_midi": 48,
"note_name": "C3",
"note_frequency": 131.09127807617188,
"note_confidence": 0.0
}
In this case, we are looking at the output of the extractor using a simplified JSON structure and only including audio features describing musical qualities. We can see that the Audio Commons Audio Extractor estimates that the analysed sound is a loop, with a tempo of 120 bpm and in F major. Note that the tool returns confidence values (in a range from 0 to 1) for some of the features it predicts and this can be used to discard information which is not reliable. For example, in the analysis results above we also see that the extractor predicts the sound has a note of C3, but the note_confidence is 0.0 therefore the note annotation should not be trusted. In this case this makes sense because the sound corresponds to a musical loop featuring many different notes and therefore a single note annotation is not meaningful at all.
What follows is another analysis example but this time of a sound effect with much less clear musical information:
{
"duration": 9.241541862487793,
"lossless": 1.0,
"codec": "pcm_s16le",
"bitrate": 705600.0,
"samplerate": 44100.0,
"channels": 1.0,
"audio_md5": "2722ac23a142ce727e0642b0a63c7347",
"loudness": -28.64586639404297,
"dynamic_range": 3.432065963745117,
"temporal_centroid": 0.5782503485679626,
"log_attack_time": 0.6950863599777222,
"filesize": 815294,
"single_event": false,
"tonality": "G# major",
"tonality_confidence": 0.5119080543518066,
"loop": false,
"tempo": 84,
"tempo_confidence": 0.42026047706604003,
"note_midi": 74,
"note_name": "D5",
"note_frequency": 608.390625,
"note_confidence": 0.0,
"brightness": 60.313207479409286,
"depth": 16.728879931862544,
"hardness": 82.90738501480826,
"roughness": 6.646583836789146
}
Note how in this case the confidence values for the musical information are lower than in the previous example. Also in this example we included the computation of four timbre models which estimate the roughness, depth, brightness and hardness of the sound. These audio features can be used to provide a new dimension with which to explore a sound collection. Checkout the Perceptual Sound Browser prototype for a real-world example of that.
Even though the analysis output that we are showing here is the simplified JSON structure, the Audio Commons Audio Extractor generate by default a JSON-LD (JSON for linked data) output compatible with the Audio Commons Ontology and other existing ontologies such as the Audio Features Ontology. Using the JSON-LD output, the analysis above would look like this:
{
"@context": {
"rdf": "http://www.w3.org/1999/02/22-rdf-syntax-ns#",
"ac": "https://w3id.org/ac-ontology/aco#",
"afo": "https://w3id.org/afo/onto/1.1#",
"afv": "https://w3id.org/afo/vocab/1.1#",
"ebucore": "http://www.ebu.ch/metadata/ontologies/ebucore/ebucore#",
"nfo": "http://www.semanticdesktop.org/ontologies/2007/03/22/nfo#"
},
"@type": "ac:AudioFile",
"ebucore:bitrate": 705600.0,
"ebucore:filesize": 529278,
"ebucore:hasCodec": {
"@type": "ebucore:AudioCodec",
"ebucore:codecId": "pcm_s16le"
},
"nfo:compressionType": "nfo:losslessCompressionType",
"ac:audioMd5": "8da67c9c2acbd13998c9002aa0f60466",
"ac:availableItemOf": {
"@type": "ac:AudioClip"
},
"ac:signalAudioFeature": [
{
"@type": "afv:Loop",
"afo:value": true
},
{
"@type": "afv:Tempo",
"afo:confidence": 1.0,
"afo:value": 120
},
{
"@type": "afv:Key",
"afo:confidence": 0.2868785858154297,
"afo:value": "G# minor"
},
{
"@type": "afv:TemporalCentroid",
"afo:value": 0.5078766345977783
},
{
"@type": "afv:MIDINote",
"afo:confidence": 0.0,
"afo:value": 74
},
{
"@type": "afv:Pitch",
"afo:confidence": 0.0,
"afo:value": 592.681884765625
},
{
"@type": "afv:Loudness",
"afo:value": -28.207069396972656
},
{
"@type": "afv:Note",
"afo:confidence": 0.0,
"afo:value": "D5"
},
{
"@type": "afv:LogAttackTime",
"afo:value": 0.30115795135498047
}
],
"ac:signalChannels": 1,
"ac:signalDuration": 6.0,
"ac:singalSamplerate": 44100.0
}
In the next section we provide some instructions about how to use the tool. Down below you’ll find a complete list of the audio features that can be estimated using the Audio Commons Audio Extractor.
Using the Audio Commons Audio Extractor
The Audio Commons Audio Extractor is expected to be used as a command line tool and run from a terminal. To facilitate its usage, the tool has been dockerized and should run without problems in any platform with Docker installed. Assuming you have Docker installed, you can easily analyze an audio file using the following command (the audio file must be located in the same folder from where you run the command, be aware that the first time you run this command it will take a lot of time as Docker will need to download the actual Audio Commons Audio Extractor tool first):
docker run -it --rm -v `pwd`:/tmp mtgupf/ac-audio-extractor:v3 -i /tmp/audio.wav -o /tmp/analysis.json -smt
The example above mounts the current directory pwd in the virtual tmp directory inside Docker. The output file audio.json is also written in tmp, and therefore appears in the current directory. You can also mount different volumes and specify paths for input audio and analysis output using the following command (read the Docker volumes documentation for more information):
docker run -it --rm -v /local/path/to/your/audio/file.wav:/audio.wav -v /local/path/to/output_directory/:/outdir mtgupf/ac-audio-extractor:v3 -i /audio.wav -o /outdir/analysis.json -smt
You can use the --help flag with the Audio Commons Audio Extractor so see a complete list of all available options:
> docker run -it --rm -v `pwd`:/tmp mtgupf/ac-audio-extractor:v3 --help
uusage: analyze.py [-h] [-v] [-t] [-m] [-s] -i INPUT -o OUTPUT [-f FORMAT]
[-u URI]
Audio Commons Audio Extractor (v3). Analyzes a given audio file and writes
results to a JSON file.
optional arguments:
-h, --help show this help message and exit
-v, --verbose if set, prints detailed info on screen during the
analysis
-t, --timbral-models include descriptors computed from timbral models
-m, --music-pieces include descriptors designed for music pieces
-s, --music-samples include descriptors designed for music samples
-i INPUT, --input INPUT
input audio file
-o OUTPUT, --output OUTPUT
output analysis file
-f FORMAT, --format FORMAT
format of the output analysis file ("json" or
"jsonld", defaults to "jsonld")
-u URI, --uri URI URI for the analyzed sound (only used if "jsonld"
format is chosen)
Note that you can use the flags t, m and s to enable or disable the computation of some specific audio features.
Included audio features
Audio file properties
These audio features are always computed and include:
duration: Duration of audio file in seconds.lossless: Whether audio file is in lossless codec (true or false).codec: Audio codec.bitrate: Bit rate.samplerate: Sample rate in Hz.channels: Number of audio channels.audio_md5: The MD5 checksum of raw undecoded audio payload. It can be used as a unique identifier of audio content.filesize: Size of the file in nytes.
Dynamics
These audio features are always computed and include:
loudness: The integrated (overall) loudness (LUFS) measured using the EBU R128 standard.dynamic_range: Loudness range (dB, LU) measured using the EBU R128 standard.temporal_centroid: Temporal centroid (sec.) of the audio signal. It is the point in time in a signal that is a temporal balancing point of the sound event energy.log_attack_time: The log (base 10) of the attack time of a signal envelope. The attack time is defined as the time duration from when the sound becomes perceptually audible to when it reaches its maximum intensity.single_event: Whether the audio file contains one single audio event or more than one (true or false). This computation is based on the loudness of the signal and does not do any frequency analysis.
Music samples and music pieces
These audio features are only computed when using the -m or -s flags and include:
tempo: BPM value estimated by beat tracking algorithm.tempo_confidence: Reliability of the tempo estimation above (in a range between 0 and 1).loop: Whether audio file is loopable (true or false).tonality: Key value estimated by key detection algorithm.tonality_confidence: Reliability of the key estimation above (in a range between 0 and 1).
Music samples
These audio features are only computed when using the -s flag and include:
note_name: Pitch note name based on median of estimated fundamental frequency.note_midi: MIDI value corresponding to the estimated note.note_frequency: Frequency corresponding to the estimated note.note_confidence: Reliability of the note name/midi/frequency estimation above (in a range between 0 and 1).
Music pieces
These audio features are only computed when using the -m flag and include:
genre: Music genre of the analysed music track (not yet implemented).mood: Mood estimation for the analysed music track (not yet implemented).
Timbre models
As described in deliverable D5.2, a number of timbre models have been developed and are included in this tool. Timbre models estimate perceptual qualities of the sounds which tend to be quite subjective and ill-defined. These audio features are only computed when using the -t flag and include:
brightness: brightness of the analyzed audio in a scale from [0-100]. A bright sound is one that is clear/vibrant and/or contains significant high-pitched elements.hardness: hardness of the analyzed audio in a scale from [0-100]. A hard sound is one that conveys the sense of having been made (i) by something solid, firm or rigid; or (ii) with a great deal of force.depth: depth of the analyzed audio in a scale from [0-100]. A deep sound is one that conveys the sense of having been made far down below the surface of its source.roughness: roughness of the analyzed audio in a scale from [0-100]. A rough sound is one that has an uneven or irregular sonic texture.boominess: bominess of the analyzedn sound in a scale from [0-100]. A boomy sound is one that conveys a sense of loudness, depth and resonance.warmth: warmth of the analyzedn sound in a scale from [0-100]. A warm sound is one that promotes a sensation analogous to that caused by a physical increase in temperature.sharpness: sharpness of the analyzedn sound in a scale from [0-100]. A sharp sound is one that suggests it might cut if it were to take on physical form.reverb: will returntrueif the signal has reverb orfalseotherwise.