The Timbre of Sound
The timbre of a sound effect plays an important role in determining if it is suitable for a project:
these snare samples sound too ‘hard’;
this synth pad doesn’t sound ‘deep’ enough;
I only want footsteps that don’t sound ‘reverberant’ .
The ability to use these timbral attributes to filter search results would enable users to find more suitable sound effects, and faster.
Sound effects libraries currently rarely include information about the timbre of each sound, because previously this needed to be added manually; a human needed to listen to each sound in order to label it. Doing this on a sound-by-sound basis resulted in inconsistent tags, sometimes labelling a sound bright because the previous sound was very dull. Also, the words used to describe the timbre have been inconsistently applied, and usually the information only included binary categories (e.g. bright or dull ) rather than a scale (e.g. a rating of the perceived brightness from 0 to 100).
Which attributes to model?
Our work in the AudioCommons project has examined what timbral attributes people use when searching for sounds - such as hard, bright, deep, warm (Pearce et al., 2017)[1] - and has used that information to create consistent terms, and to determine which attributes users search for most frequently. Figure 1 shows how frequently common timbral descriptors were searched in freesound.org. For an interactive version of this, go to http://www.iosr.uk/projects/AudioCommons/sunburst_freesound.php.
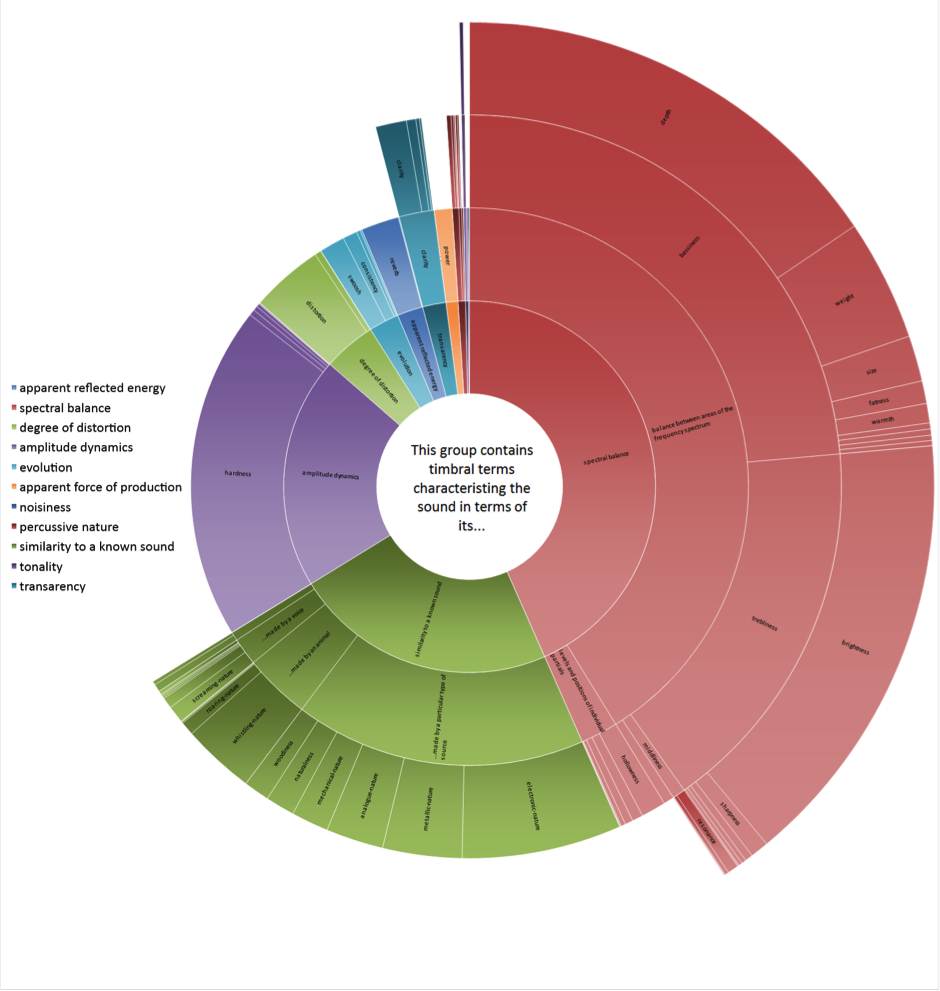
Figure 1. How often each timbral attribute is searched on freesound.org
We have used this information to prioritise our work on creating perceptual models to measure the most useful timbral properties of sounds; those that are used the most. The perceptual models can process a library of sound files, and predict the perceived timbral properties of each sound. Now that we have created perceptual models for the most commonly used attributes, all sounds in a library can be automatically labelled with consistent timbral attributes, on scales that allow comparison between sounds.
Models have been developed for Hardness, Depth, Brightness, Warmth, Roughness, Sharpness, Boominess, and Reverberation. These attributes were selected since they were the most common that people search for in freesound. These models (except for Reverberation) produce numerical predictions of the extent of each attribute. For example, a sound with a predicted hardness of 10 would sound fairly soft, whereas values of 90 would sound very hard. The model of Reverberation is a classification model, able to determine if a sound effect sounds dry (no reverb) or wet (some/lots of reverb).
How were the models developed?
Most models were developed using a similar method: collecting subjective ratings of the attribute using a large pool of sound effects downloaded from freesound; using literature to identify suitable features to extract from the audio files; developing new methods to predict features that affect our perception of the attribute; selecting the most appropriate features to use in a prediction model; and determining the optimum combination of the features using regression modelling to predict the subjective ratings.
The models are still in a prototype stage, and improvements are being made regularly to better fit the subjective ratings of each attribute. They are implemented in Python and are available from the project’s GitHub page (for the most up-to-date versions) or installable from PyPI (updated for significant changes).
Currently, each model is coded as an independent function, but there are future plans to develop a timbral extractor function to efficiently extract all timbral attributes with a single call, and have the models integrated into the Audio Commons Extractor.
Searching with timbre
The Sound Map Visualizer, developed by MTG, was a prototype tool for showing how sounds’ metadata from freesound.org could be used to graphically distribute sounds. Below is a modified version of this interface, built on a collection of 424 samples. The metadata for each of the timbral attributes were calculated offline using the developed algorithms. In this example, the x and y axes can be set using the dropdown menus, distributing the sounds by the selected attributes. Sounds of only specific source types can also be selected via the drop down menus, or limiting sounds just to reverberant or non-reverberant sounds.
Explore the Sound Map Visualiser Demo in full screen here.
Once the metadata from these timbral models has been fully integrated in to the Audio Commons Ecosystem, users will be able to find only soft sounding snare samples, deep synth pads, or footsteps without reverb.
References
[1] Pearce, A., Brookes, T., & Mason, R. (2017, June). Timbral attributes for sound effect library searching. In Audio Engineering Society Conference: 2017 AES International Conference on Semantic Audio. Audio Engineering Society.